




Są w życiu rzeczy, które warto i są takie, które się opłaca… nie zawsze to, co warto — się opłaca. Nie zawsze to, co się opłaca – warto.
Parafraza słów Władysława Bartoszewskiego nie jest przypadkowa. Decyzję czy warto/opłaca się skorzystać z możliwości multi cloud rozważa dzisiaj coraz więcej organizacji. Jakie konsekwencje wynikają z podjętej decyzji? O tym w poradniku, gdzie krok po kroku przeanalizuję proces doboru odpowiedniej strategii chmurowej dla organizacji. W Internecie przeczytasz skrajne opinie; od zwolenników strategii multi cloud po przeciwników i typowego konsultingowego podejścia “to zależy” ☺ Dlatego nie przedłużając, zaczynam zgłębiać temat.
Adaptacja chmury publicznej w dużych przedsiębiorstwach w Polsce
Wg. wszystkich raportów chmura publiczna powszechnieje, nie zastanawiamy się już czy, tylko jak wykorzystać potencjał chmury obliczeniowej. Dostawcy za rosnącymi potrzebami partnerów udoskonalają swoje usługi o dodatkowe funkcjonalności. Zespoły IT składają działające rozwiązania z dostępnych klocków, a integratorzy mają pełne ręce roboty. My konsumenci uczymy się na błędach… Dzisiaj oczkiem w głowie są zagadnienia z optymalizacji i maksymalizacji wykorzystania chmury: a) innowacje w obszarze data (AI-Driven) b) FinOps (dlaczego wydajemy tak dużo? O tym napiszę następnym razem).
Nadal oczywiście borykamy się z długiem technologicznym i kulturą silosów w organizacjach (o tym przeczytasz w moim artykule na Linkedin Transformacja chmurowa w instytucji finansowej w 3 miesiące czy 10 lat? Studium przypadku).
Analizując np. sektor finansowy zaobserwujemy jednoznaczny trend multi cloud. Większość instytucji wykorzystuje dwie chmury publiczne plus lokalne centra przetwarzania danych (w tym m.in. chmury prywatne). W PKO BP, Banku Pekao, ING Banku Śląskim popracujemy z technologiami Microsoft Azure i Google Cloud Platform (GCP). Nest Bank wykorzystuje Microsoft Azure i Amazon Web Services (AWS). U innowatorów adopcji chmury w Polsce: mBank i Bank Millennium skorzystamy nawet z trzech dostawców: Azure, GCP i AWS. Podobnie jak w BNP Paribas Bank Polska, który przez swoje powiązanie z Grupą BNP Paribas wykorzystuje możliwości IBM Cloud, Azure, GCP czy też Alior Banku, którzy korzysta z technologii Azure, GCP i Oracle Cloud Infrastructure (OCI).
W Allianz Polska również wykorzystujemy dwóch dostawców Microsoft i AWS. Z racji przejęcia spółek Aviva Polska przez Allianz Group w 2022 r. i globalnej strategii dywersyfikacji ryzyka wykorzystujemy zarówno usługi AWS jak i Azure.
Poza branżą regulowaną w jednej z największych firm mediowych Ringier Axel Springer Polska, która w tym roku przeniosła po 5 latach całą organizację do chmury AWS również wykorzystywane są rozwiązania analityki danych GCP (wraz z ofertą Google Ads) oraz narzędzia Modern Workplace Microsoft 365.
Naturalnie pojawiają się pytania;
- Przedsiębiorstwo, które korzysta na co dzień z narzędzi M365 i wykorzystuje usługi AWS do udostępnienia aplikacji sprzedażowych swoich produktów jest już organizacją multi cloud?
- Czy dopiero w sytuacji kiedy firma jest w stanie wdrożyć identyczną aplikację w drugiej chmurze w zadeklarowanym czasie Business Continuity Plan (BCP)?
Oczywiście instytucja ze zbudowanymi landing zones w dwóch chmurach, przeszkolonym personelem, jedną tożsamością, jednolitym: SSO (Single Sign-On), procesem CI/CD, monitoringiem, wspólnymi standardami bezpieczeństwa itd. szybciej uruchomi identyczną aplikację u drugiego dostawcy chmurowego, niż organizacja tylko z udokumentowanym planem wycofania (exit plan) i nieprzetestowanym procesem.
Jednak każdy ma swoją własną definicję multi cloud. Wszystkie z powyższych instytucji mają inną wizję rozwoju biznesu, unikalne podejście do szacowania i akceptacji ryzyka, określony budżet na R&D oraz odrębną strategię IT dla długu technologicznego, Disaster Recovery (DR) i BCP. To od indywidualnych potrzeb tego co chcemy osiągnąć, jakie środki chcemy zaangażować i odpowiedzi na pytanie po co (why?) zaczyna się cała dyskusja o multi cloud.
Dla mnie osobiście chmura publiczna jest narzędziem do realizacji celów biznesowych, a multi cloud to wykorzystywanie potencjału więcej niż jednej z chmur publicznych jednocześnie.
Skoro mowa o DR i BCP to jak to robią inni na świecie? Poniżej analiza firm w modelu SaaS (Software as a Service), które oparły swój biznes wyłącznie na chmurze.
Infrastruktura IT Top10 firm Cloud 100 computing companies

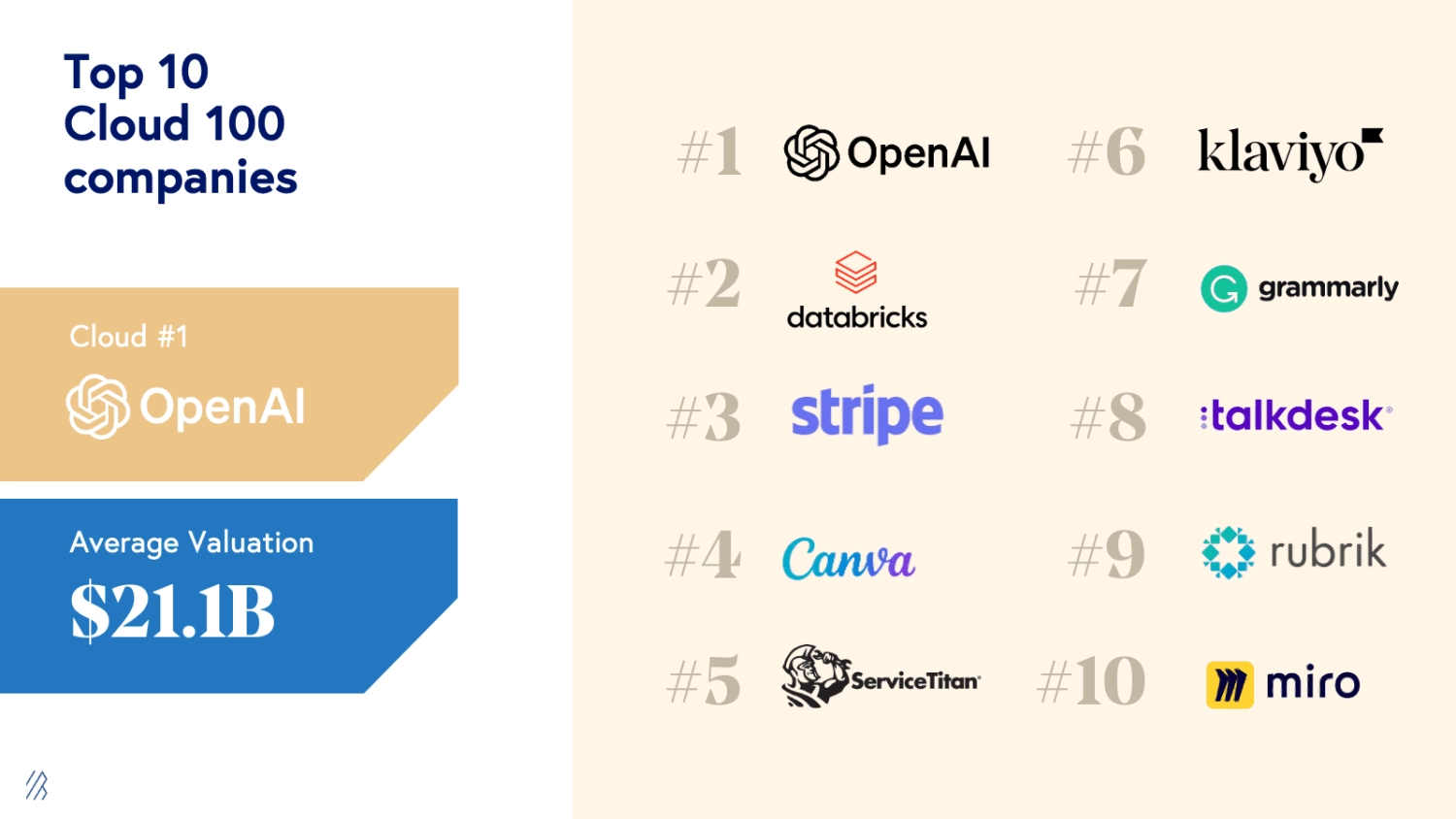
Firmy takie jak OpenAI (nr 1 na liście) oferująca produkty AI, Stripe (nr 3) z multinational financial services oraz ServiceTitan (nr 5) sprzedająca trade industry software wykorzystują technologie od dwóch dostawców chmurowych Microsoft i AWS. [2-5]
Databricks (nr 2), który oferuje platformę analityczną Data i AI korzysta aż z czterech dostawców: AWS, GCP, Microsoft, Oracle Corporation. [6]
Co ciekawe aż 4 firmy: Canva (4) visual communication platform, Klaviyo (6) marketing automation, Grammarly (7) communication assistance oraz Miro (10) digital collaboration oparły swój biznes wyłącznie na infrastrukturze AWS. [7-11]
Natomiast Talkdesk (nr 8), który oferuje cloud contact center wykorzystuje 3 niezależne regiony AWS (US, Canada, EU) oraz 1 region GCP dla backupu baz danych. [12,13]
Rubrik (nr 9), który sprzedaje usługi data security, wykorzystuje globalną infrastrukturę chmurową oraz korzysta z usług trzech dostawców: Microsoft (Azure), AWS i GCP. [14,15]
Po analizie widać bardzo duże rozbieżności między cloud computing companies i ich strategicznym podejściem. Od wykorzystywania tylko jednego dostawcy chmurowego po aż czterech. Można jednak postawić hipotezę, że czym bardziej newralgiczny proces/świadczona usługa dla klienta końcowego tym dostawca sam wykorzystuje podejście multi cloud. Zapewnienie kontaktu z klientem przez call center jest ważniejsze niż brak możliwości przygotowania fantastycznej grafiki. Wyjątkiem od reguły jest oczywiście infrastruktura IT firmy Klaviyo (marketing automation). Dlaczego? Jedną z odpowiedzi analizuję poniżej.
Incydenty dostawców chmurowych oraz ich wpływ na architekturę rozwiązania
Przyjrzyjmy się udokumentowanym awariom z ostatnich lat u trzech głównych dostawców chmury publicznej AWS, Microsoft i Google.


O każdym incydencie, diagnozie przyczyny źródłowej i analizie rozwiązania można przeczytać na stronie Post-Event Summaries (amazon.com) Aktualny status dostępności usług zweryfikujesz pod adresem www AWS Health Dashboard | Global (amazon.com).
Jednocześnie, jeśli ktoś uważał, że niemożliwa jest globalna przerwa single point of failure (SPOF) w dostępie do usług chmurowych to jest w błędzie. Niezależnie od redundancji na poziomie regionów (setki km), stref dostępności, data centers itp. to awaria sieci z 25 stycznia 2023 r. potwierdziła ryzyko:

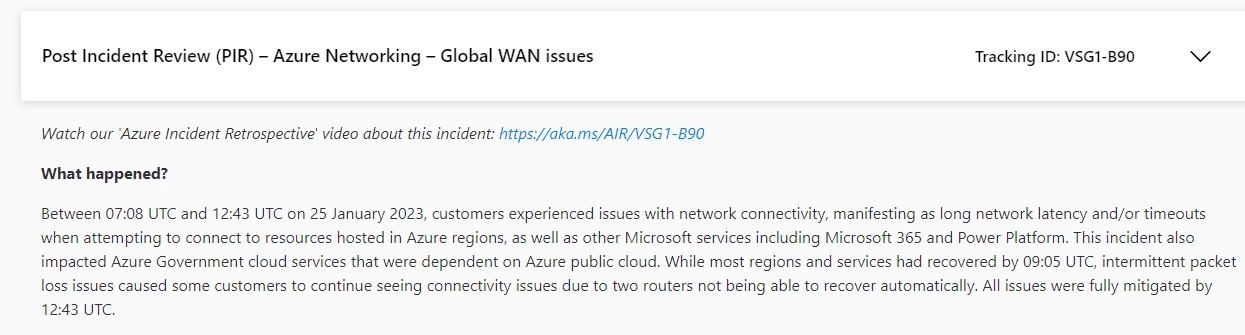

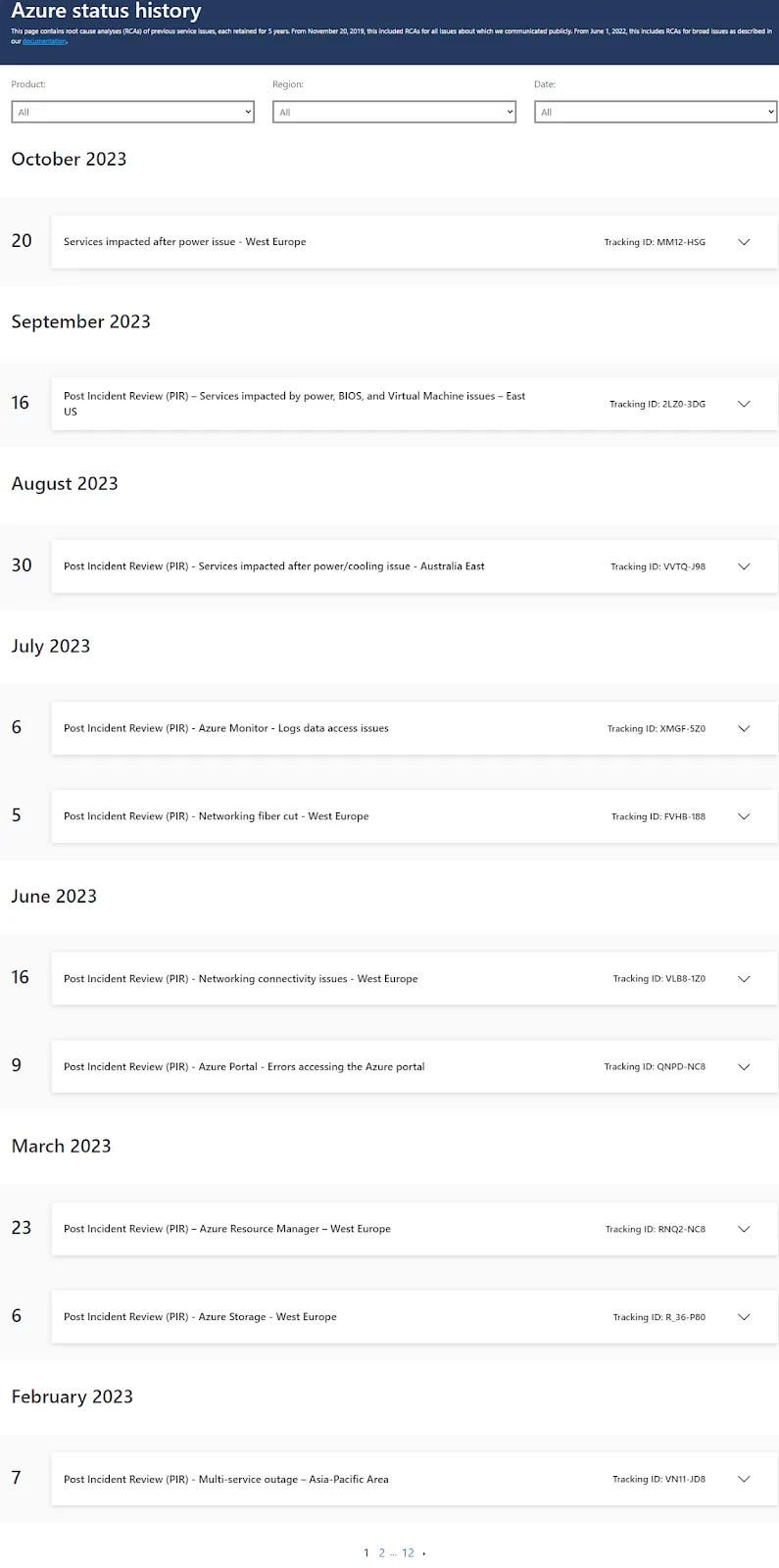
Pocieszający jest fakt, że Microsoft usuwa awarie sprawnie, ale nasze procesy biznesowe są zatrzymane. O każdym incydencie w Azure, diagnozie przyczyny źródłowej i rozwiązaniu przeczytasz na stronie Azure status history. Aktualny status dostępności usług można zweryfikować pod adresem Azure status.
Nawet w czasie pisania artykułu trwał incydent w GCP ☺

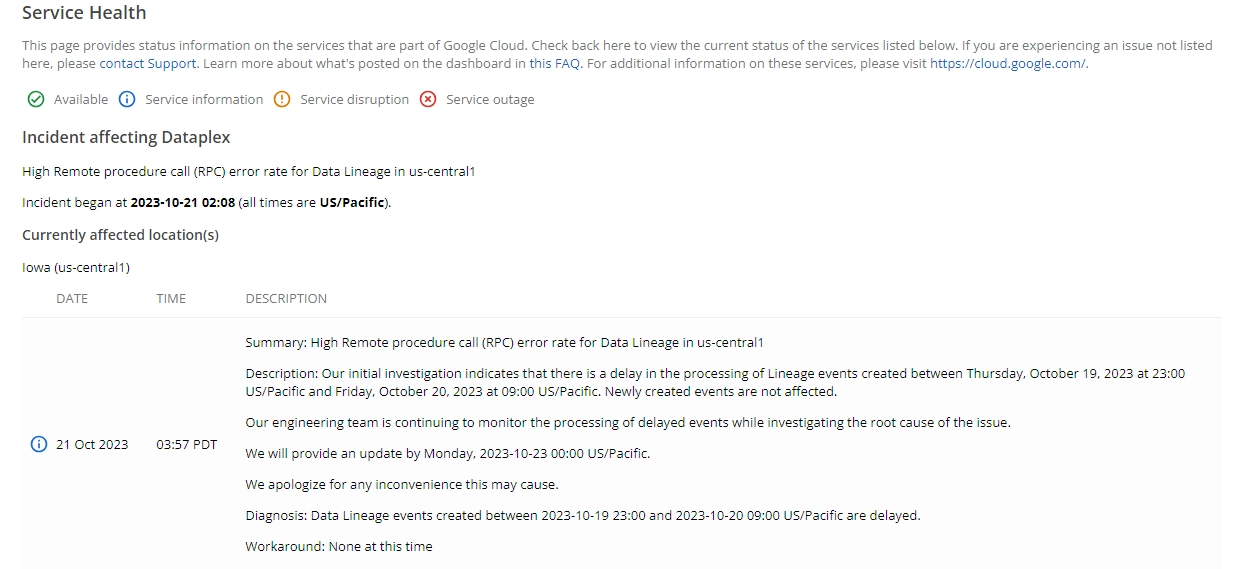
Poniżej wycinek historii incydentów tylko dla jednej usługi Google BigQuery:

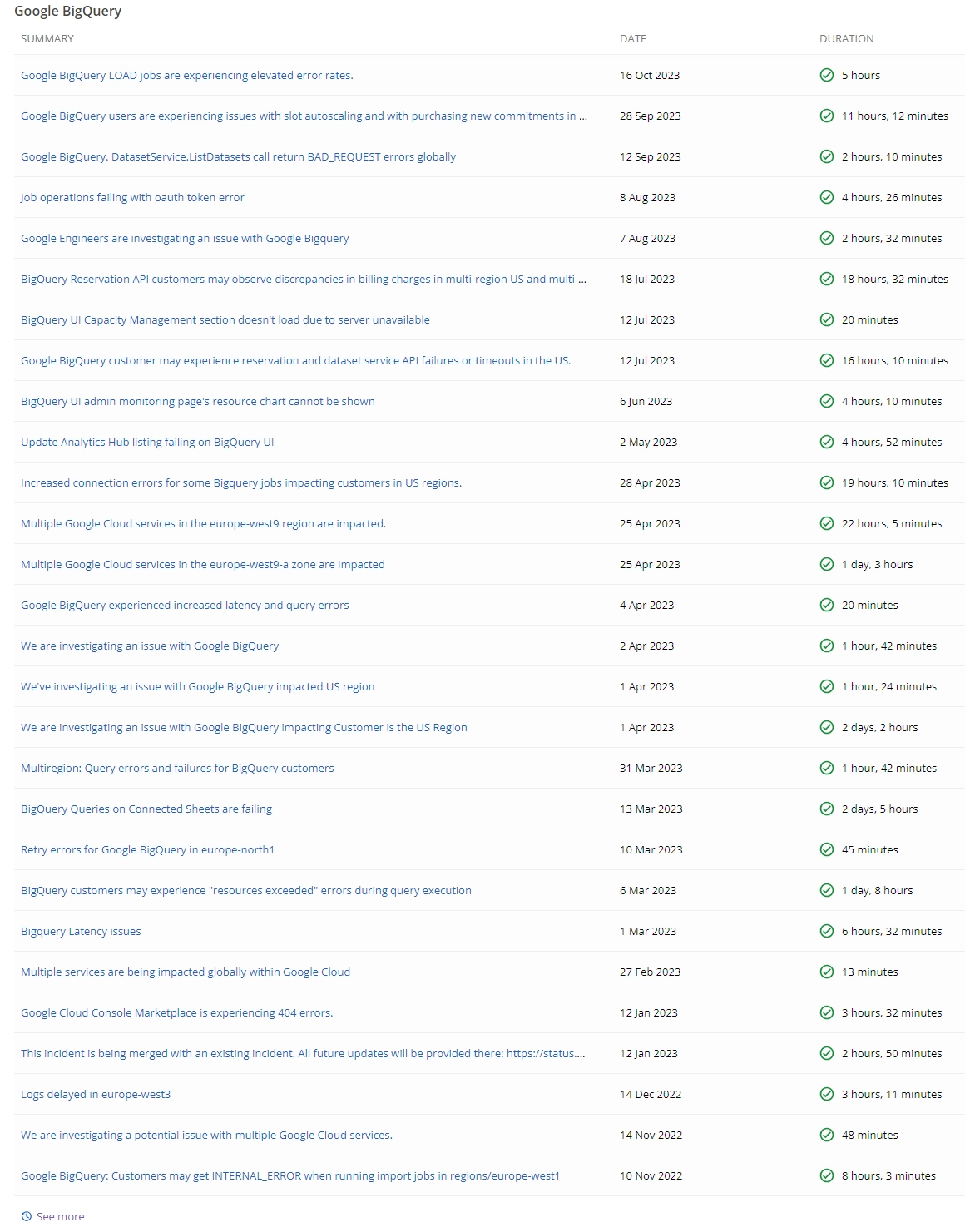
Wszystkie incydenty dla GCP, diagnozach przyczyn źródłowych i rozwiązaniach dostępne są na stronie GCP status history. Aktualny status dostępności usług można zweryfikować pod adresem Google Cloud Service Health.
Podsumowując ww. zestawienie najważniejszymi incydentami, z jakimi się spotkamy w chmurze to:
- Brak łączności sieciowej, opóźnienia;
- Chwilowe niedostępności usług, timeout z API usługi;
- Całkowite przestoje funkcjonowania usług;
- Całkowite awarie regionów.
Decydując się na strategię cloud należy uwzględnić ww. zagrożenia w procesach BCP, DR i odpowiednio się przed nimi zabezpieczyć stosując replikacje, redundancje i odporność (resilience). Należy wykorzystać odpowiednie wzorce architektoniczne dla naszych aplikacji: Retry, Circuit Breaker, Health Endpoint Monitoring itp. [16]
Niestety wszystkie dodatkowe zabezpieczenia wpływają na koszty inwestycji, dlatego na wstępie należy urealnić parametry poziomu świadczonych usług Service-Level Objective (SLO), Recovery Time Objective (RTO), Recovery Point Objective (RPO), za które zapłaci sponsor projektu.☺ [17]
HA na poziomie multi-cloud gwarantuje najlepsze bezpieczeństwo, ale poziom złożoności i skomplikowania infrastruktury IT rośnie liniowo. Gryzie się to z zasadą Keep It Simple Stupid (KISS). Nie komplikuj niepotrzebnie. Dlatego warto wcześniej zmienić spojrzenie na ten sam problem i spróbować innej koncepcji architektury rozwiązania. Do analizy wpływu i ochrony przed incydentami na pewno przydadzą się testy chaotyczne (chaos testing) np. The Simian Army znany z Netflixa. [18]
Największe korzyści (oszczędności) poczynimy dzięki wdrożonej profilaktyce inżynierii chaosu. Lepiej zapobiegać niż leczyć. Dzięki niej unikniemy kosztownych przerw w dostarczaniu usług. Eksperci z Netfliksa opisują przypadki zastosowania inżynierii chaosu w biznesie. Wykorzystam zaproponowany wzór do obliczenia ROI dla strategii multi-cloud. [19]
Zwrot inwestycji multi-cloud
Nie warto i nie opłaca się „robić chmury dla chmury”. Należy kontrolować wartość, koszt i termin zwrotu z inwestycji, przy uwzględnianiu całego kontekstu projektowego.


Dla uproszczonego wskaźnika zwrotu z inwestycji ROI (Return on investment) multi-cloud można przyjąć następujące nakłady finansowe:
KI - całkowity koszt integracji infrastruktury IT dla dwóch chmur (tożsamość monitoring, bezpieczeństwo, proces CI/CD) KO - całkowity koszt obsługi operacyjnej drugiej chmury (procesy, zamówienia) KD - koszt działania drugiego zespołu cloud (rekrutacja, upskilling, reskilling) KA – koszt przestojów, incydentów wywołanych wzrostem skomplikowania infrastruktury IT
oraz uwzględnić przewidywalny zysk:
ZO – oszczędności i profity uzyskane z możliwości wykorzystania drugiego dostawcy chmurowego ZD – zysk z dywersyfikacji ryzyka (brak całkowitego przestoju)
Specjalnie nie uwzględniam w obliczeniach kosztów wynagrodzenia dla drugiego zespołu chmurowego, ponieważ gdybyśmy zostali przy jednym dostawcy to i tak musielibyśmy zatrudnić specjalistów do nowego obszaru działalności (oczywiście w sytuacji pełnego już obciążenia zespołu i tych samych kwalifikacji/pensji). Tak samo zysk ze standaryzacji usług IT został zjedzony przez koszty integracji.

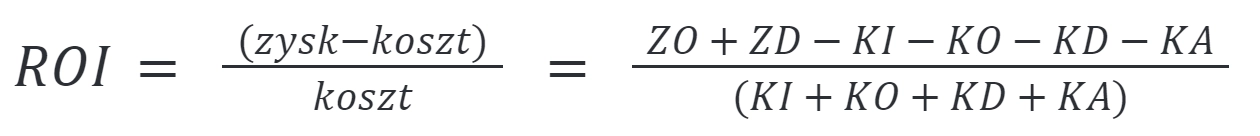
Przyjmijmy dla prostego scenariusza, w którym w ciągu 12 miesięcy:
ZO = zarobiliśmy/zaoszczędziliśmy dzięki drugiej chmurze 200 000 zł,
ZD = zapobiegliśmy przerwom w działaniu usług za 20 000 zł,
KI = całkowity koszt integracji usług IT wyniósł 500 000 zł,
KO = koszty operacyjne wynoszą 10 000 zł,
KD = całkowite koszty działania drugiego zespołu to 200 000 zł,
KA = przestoje wywołane złożonością systemów 20 000 zł.

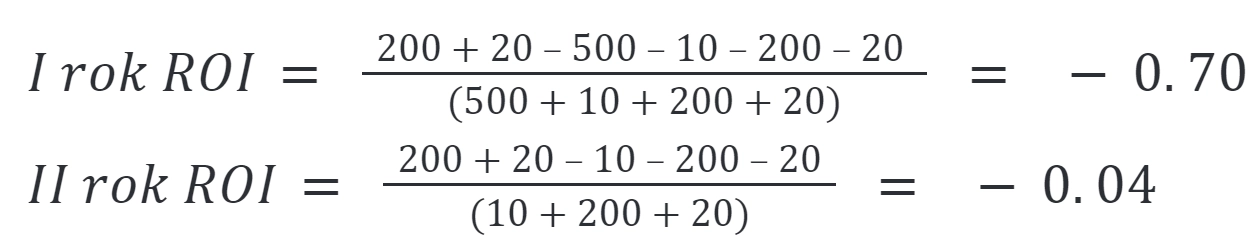
Pierwszego roku ponosimy stratę w wysokości aż -70% poniesionych nakładów inwestycyjnych, ale drugiego roku po odjęciu kosztów integracji usług IT, strata wynosi już tylko -4%. Oczywiście każdy wygenerowany, dodatkowy zysk dzięki wykorzystaniu możliwości drugiej chmury pozytywnie wpłynie na ostateczny wynik. Na pewno w każdej firmie poszczególne składowe rozłożą się inaczej, ale bez wyjątku wszyscy muszą znaleźć policzalne korzyści z podejścia multi cloud w perspektywie długofalowej (incentive od dostawcy w końcu się skończy). Inaczej wynik zawsze będzie na minusie.
Po czterech rozdziałach nadal nie widać rozstrzygnięcia, dlaczego część organizacji zdecydowała się na strategię multi cloud :) Nadal nie było również obiecanego procesu doboru strategii. Nie przejmuj się! O tym już w kolejnej części poradnika.
Przypisy:
- https://www.forbes.com/lists/cloud100
- https://openai.com/research/infrastructure-for-deep-learning 3.https://openai.com/research/scaling-kubernetes-to-7500-nodes
- https://stripe.com/en-pl/legal/service-providers
- https://medium.com/servicetitan-engineering/problems-we-solve-38ec4a275189
- https://www.databricks.com/legal/databricks-subprocessors
- https://aws.amazon.com/solutions/case-studies/canva-2019/
- https://developers.klaviyo.com/en/docs/klaviyos_architecture
- https://www.grammarly.com/blog/engineering/moving-onpremise-macos-to-aws/
- https://www.grammarly.com/blog/engineering/scaling-aws-infrastructure/
- https://miro.com/blog/miro-aws-partnership/
- https://infra-cloudfront-talkdeskcom.svc.talkdeskapp.com/talkdesk_com/talkdesk-global-communications-gcn-brochure.pdf
- https://support.talkdesk.com/hc/en-us/articles/201760169-Where-are-your-servers-located
- https://www.rubrik.com/trust
- https://www.rubrik.com/legal/rubrik-subprocessors
- https://docs.microsoft.com/en-us/azure/architecture/patterns/
- https://learn.microsoft.com/en-us/azure/cloud-adoption-framework/manage/monitor/service-level-objectives
- https://netflixtechblog.com/the-netflix-simian-army-16e57fbab116
- https://blog.aspiresys.pl/technology/chaos-monkey-how-netflix-deals-with-resilience/



