




Z artykułu dowiecie się więcej o Kubernetes (K8s). W skrócie jest platforma, na której są instalowane aplikacje biznesowe i operacyjne. Dowiecie się dlaczego, według autora, K8s jest odpowiednim rozwiązaniem do pełnienia funkcji jeśli nie platformy, to przynajmniej jej solidnych podwalin. W dalszej części artykułu wyjaśniamy, dlaczego instalując K8s, warto postawić na Infrastructure as Code, na przykładzie skryptu w Terraform „stawiający” K8s na Digital Ocean.
Ponadto opisane zostało przygotowanie aplikacji napisanej w języku Java i wykorzystującej biblioteki ze stajni Spring Framework do zainstalowania jej na K8s. Dowiecie się też więcej na temat sposobów „konteneryzacji” aplikacji Java. Pokazane w artykule przykłady zawierają najlepsze praktyki konfiguracji niektórych artefaktów K8s. W ostatnim rozdziale wymienione zostały aplikacje, które ułatwiają codzienną pracę z Java, Java@K8s i K8s.
Dlaczego Kubernetes?
Cytując kubernetes.io/pl: “Kubernetes, znany też jako K8s, to otwarte oprogramowanie, służące do automatyzacji procesów uruchamiania, skalowania i zarządzania aplikacjami w kontenerach”. To nie jedyny produkt z podobnym opisem, bo innym przykładem może być OpenShift albo Docker Swarm i jeśli trafiłeś tutaj, bo musisz wybrać któryś produkt z tej rodziny, to za Kubernetesem przemawiają następujące argumenty:
- Bazuje na systemie Borg, który z sukcesem, od wielu lat dźwiga serwisy Google.
- Ma duży i dynamicznie rozwijający się ekosystem.
- Szeroko dostępne są serwisy, wsparcie i dodatkowe narzędzia.
- System sprawdzony na wielu produkcjach.
- Jest częścią CNCF. Ma bardzo bogatą dokumentację, nawet pewna jej część napisana jest w języku polskim.
Wymagania: Żeby w pełni korzystać z możlwości K8s konieczna jest aplikacja w kontenerze. Twórcy umożliwili pracę tylko z kontenerami. Czy w ten sposób wskazują sposób, w jaki obecnie powinny być robione aplikacje? Być może właśnie tak jest. Poznajcie najważniejsze zalety kontenerów:
- Efektywne wykorzystanie zasobów maszyny.
- Kontener buduje się szybko i łatwiej niż VM.
- Spójność aplikacji na różnych środowiskach: upraszczając - aplikacja działa w ten sam sposób niezależnie czy jest uruchamiana podczas developmentu na laptopie, czy zainstalowana w chmurze.
- Przewidywalna wydajność, poprzez dedykowanie zasobów.
- Aplikacja może być uruchomiona na różnych systemach operacyjnych i platformach chmurowych: Ubuntu, Container Optimized System, Windows, dowolnego dostawcy usług chmurowych itd.
Co zapewnia Kubernetes:
- Jasno opisane API + szeroka adaptacja produktu = duży wybór aplikacji, rozwiązujących problemy operacyjne oraz biznesowe.
- Samo zainstalowanie aplikacji na produkci nie jest wystarczające. Trzeba dbać o nią – na przykład uruchomiać ponownie, jeśli z jakiegoś powodu przestała działać lub przenieść na inną maszynę, kiedy obecna “niedomaga”.
- Balansowanie ruchu. Uruchomiając kilka instancji aplikacji, Kubernetes może bilansować ruch między nimi.
- Umożliwia pracę z różnymi systemami składowania danych w ten sam sposób.
- Instalacja aplikacji, jej zmiana i wycofywanie jest automatyczne. Używając składni, Kubernetesowi opisuje się stan oczekiwany, a on zajmuje się jego realizacją.
- Zarządzanie dostępnymi zasobami. Po dostarczeniu klastra maszyn Kubernetesowi, zleca się uruchamianie aplikacji, z kolei Kubernetes zajmuję się wyszukiwaniem odpowiedniej maszyny, aby jak najefektywniej wykorzystać zasoby.
- Monitoruje aplikacje i automatycznie je restartuje albo wymienia na nowe, jeśli przestają działać. Co więcej, nie kieruje ruchu do aplikacji jeśli nie są one gotowe.
- Udostępnia narzędzia do zarządzania informacjami poufnymi i konfiguracją.
Pojęcie “Infrastructure as Code”
Pojęcie Infrastructure as Code (IaC) nie jest nowe, ale dopiero od niedawna stało się standardem w tworzeniu infrastruktury i jej komponentów. Poprzez infrastrukturę rozumiemy np. utworzenie sieci i podsieci u dostawcy chmury publicznej lub „postawienia” klastra Kubernetes na wirtualkach.
IaC nakazuje tworzyć infrastrukturę wyłącznie jako kod, w narzędziach dedykowanych. Narzędzia cechują się tym, że kod można uruchamiać bezpiecznie wiele razy, nie narażając się na nadpisanie albo usunięcie tego co już działa. Systemy takie powinny też umożliwiać postawienie infrastruktury od nowa.
Rozwiązaniem nierzetelnym i niebezpiecznym, chociaż najszybszym, jest zainstalowanie komponentów i ich skonfigurowanie poprzez kliknięcie albo uruchomienie instalatorów ręcznie. Nie zawsze notujemy, co dzieje się podczas takie go uruchamiania. Dlatego też nie jest to dobre rozwiązanie. Dlaczego jeszcze? Poniżej powody:
- Jest to nieefektywne czasowo, a co za tym idzie również finansowo.
- Jest to niebezpieczne, bo może się nam wydawać, że notatki są kompletne. Jednak z uwagi na to, że nigdy nie były powtórzone od początku, to jakiegoś kroku może brakować. W sytuacji kiedy np. trzeba coś zainstalować i jeszcze skonfigurować, to nie używając dedykowanego narzędzia, praktycznie niemożliwym staje się rzetelne udokumentowanie kroków.
Używanie dedykowanych systemów umożliwia wykorzystanie aplikacji i technik, które powstały wokół IaC. Na przykład technika Shift Left zakłada, że najtańszym (nie tylko pod względem finansowym) miejscem na wyłapanie błędów i nieprawidłowości w produkcie technicznym jest faza budowy. Stąd też kładzie się duży nacisk na testowanie i analizowanie produktu jak najbliżej fazy budowania. Przykładami są:
- Pisanie testów jednostkowych i uniemożliwianie zmiany kodu, póki testy nie pokrywają np. 80% całego kodu.
- Użycie analizatora wykorzystywanych bibliotek w celu wykrycia tych „z dziurami” bezpieczeństwa.
- Używanie Snyk, checkov, czyli narzędzi do analizy kodu Terraform (i nie tylko) i wskazywanie miejsc niebezpiecznych albo niezgodnych z tak zwanymi „best practices”. Jeśli stawiając infrastrukturę instalowany jest system operacyjny z dziurą bezpieczeństwa, albo utworzymy publicznie dostępny zasób S3, to te systemy informują o takiej sytuacji.
Kubernetes a Java
Dostosowanie aplikacji, w tym aplikacji Java, do zainstalowania na produkcji jest często kontekstowe, zależne od tego, w jakiej firmie i z kim pracujesz. Nie mniej można wyróżnić praktyki, które są uznane przez większość programistów.
Konfiguracja jest niezależnym artefaktem
Niezależnie od tego, jak jest zbudowana aplikacja – jar, war, Docker image, konfiguracja w większości przypadków nie powinna być częścią wspomnianego artefaktu. Aplikacja powinna jej szukać na systemie plików albo np. odpytywać serwis konfiguracyjny. Jeśli jest częścią „pakietu", wówczas zmiana konfiguracji będzie wyzwalała proces budowania aplikacji. To oznacza, że:
- W przypadku developmentu niepotrzebnie wydłuża proces „develop – release – test”.
- W dojrzałych projektach Continuous Integration pipeline jest rozbudowany i wieloetapowy, co znacznie wydłuża proces.
- Spowalnia „hot fixing” i „troubleshooting”. W przeciwnym przypadku można byłoby zmienić konfigurację bezpośrednio na środowisku i uruchomiać ponownie aplikację (bez jej przebudowy), która zaczyta nowy config.
Poniżej przykładowa konfiguracja aplikacji Java w Spring Framework - /etc/app/application.yaml:
1 app: 2 welcome-message: Welcome! 3 management: 4 server.port: 8090
Natomiast to jest konfiguracja biblioteki logującej - /etc/app/logback.xml
1<?xml version="1.0" encoding="UTF-8"?><configuration scan="true" scanPeriod="30 seconds"> <appender name="stdout" class="ch.qos.logback.core.ConsoleAppender"> <encoder class="net.logstash.logback.encoder.LogstashEncoder"/> </appender> <root level="info"> <appender-ref ref="stdout"/> </root></configuration>
Uruchamiając tę aplikację, trzeba wskazać miejsca, gdzie te dwa pliki konfiguracyjne się znajdują. Można to zrobić poprzez argumenty JVM:
1Java … -Dspring.config.location=file:/etc/app/ -Dlogback.configurationFile=/etc/app/logback.xml -Dlogback.statusListenerClass=ch.qos.logback.core.status.OnConsoleStatusListener
Co w przypadku instalacji aplikacji na Kubernetes można zrobić następującym sposobem:
- Tworzony jest ConfigMap z treścią z application.yaml, który później zostanie zamontowany pod odpowiednią ścieżkę w kontenerze:
1kind: ConfigMapapiVersion: v1metadata: name: app-configdata: application.yaml: |- app: 2 welcome-message: Welcome! 3 management: 4 server.port: 8090
- Tworzony jest kolejny ConfigMap z treścią z logback.xml, który również będzie zamontowany w kontenerze:
1kind: ConfigMapapiVersion: v1metadata: name: app-config-logbackdata: logback.xml: |- <?xml version="1.0" encoding="UTF-8"?> <configuration scan="true" scanPeriod="30 seconds"> <appender name="stdout" class="ch.qos.logback.core.ConsoleAppender"> <encoder class="net.logstash.logback.encoder.LogstashEncoder"/> </appender> <root level="info"> <appender-ref ref="stdout"/> </root> </configuration>
- Instalując aplikację na Kubernetes, montowane są poniższe pliki konfiguracyjne:
1... 2spec: 3... 4 template: 5... 6 spec: 7... 8 containers: 9 - name: k8s-java-hello-world 10 livenessProbe: 11 httpGet: 12 path: /health 13 port: 8090 14... 15 volumeMounts: 16 - mountPath: /etc/app/application.yaml 17 name: application-configuration 18 subPath: application.yaml 19 readOnly: true 20 - mountPath: /etc/app/logback.xml 21 name: application-configuration-logback 22 subPath: logback.xml 23 readOnly: true 24... 25 env: 26 - name: "JAVA_TOOL_OPTIONS" 27 value: | 28 -Dspring.config.location=file:/etc/app/ 29... 30 volumes: 31 - configMap: 32 name: app-config 33 name: application-configuration 34 - configMap: 35 name: app-config-logback 36 name: application-configuration-logback
Udostępnij status aplikacji
Aby Kubernetes mógł wykonać jedną ze swoich odpowiedzialności, należy:
- Uruchomić ponownie aplikację, jeśli ta nie działa prawidłowo (na przykład Spring Context nie wstał).
- Nie kierować ruchu do aplikacji, jeśli ta jest niegotowa (na przykład Spring Context jeszcze nie wstał albo nie udaje się połączyć z Kafka).
Jedną z możliwości jest dodanie zależności Spring Actuator:
1<dependency> 2 <groupId>org.springframework.boot</groupId> 3 <artifactId>spring-boot-starter-actuator</artifactId> 4 <version>${spring-boot.version}</version> 5</dependency>
Aktywacja:
1kind: ConfigMap 2... 3data: 4 application.yaml: |- 5 app: 6 welcome-message: Welcome! 7 management: 8 server.port: 8090 9 health.binders.enabled: true 10 endpoints: 11 web: 12 base-path: / 13 exposure.include: [health] 14 enabled-by-default: false 15 endpoint: 16 health.enabled: true
Wskazanie ścieżki do zasobu Health Kubernetes:
1kind: Deployment 2... 3spec: 4... 5 template: 6... 7 spec: 8... 9 containers: 10 - name: k8s-java-hello-world 11... 12 livenessProbe: 13 httpGet: 14 path: /health 15 port: 8090
Czas by aplikacja opowiedziała o sobie
Bardzo ważna jest wiedza o funkcjonowaniu aplikacji – musimy wiedzieć, czy aplikacja „chodzi”, czy odnotowany jest ruch, jak długo wykonuje zadania biznesowe (np. ile trwa odpowiedź na zapytanie HTTP), ile zadań kończy się błędami, jakie jest zużycie procesora i pamięci, jakie są pauzy GC itd. Dopiero mając tę wiedzę można wnioskować o poprawny UX.
Wyżej użyta biblioteka Spring Actuator instrumentuje wiele popularnych framework’ów, takich jak Spring MVC, RestTemplate, Kafka Client itd. Co oznacza, że nie robiąc praktycznie nic, aplikacja informuje np. o liczbie request’ów HTTP, ich statusie wykonania jak długo trwały. W przypadku Kafka takie informacje jak ilość wysłanych bajtów, LAG per topic itd.
1<dependency> 2 <groupId>org.springframework.boot</groupId> 3 <artifactId>spring-boot-starter-web</artifactId> 4 <version>${spring-boot.version}</version> 5</dependency>
Musimy jeszcze zdecydować jakim narzędziem te metryki będą zbierane. Spring Actuator pod spodem używa Micrometer a jego implementację wspiera format rozumiany przez Prometheus. Aplikacje składowe Kubernetes generują metryki właśnie w tym standardzie. Wskazujemy ten standard poprzez dodanie zależności:
1<dependency> 2 <groupId>io.micrometer</groupId> 3 <artifactId>micrometer-registry-prometheus</artifactId> 4 <version>${micrometer-registry-prometheus.version}</version> 5</dependency>
Następnie aktywujemy endpoint:
1kind: ConfigMap 2... 3data: 4 application.yaml: |- 5 app: 6 welcome-message: Welcome! 7 management: 8 server.port: 8090 9 health.binders.enabled: true 10 endpoints: 11 web: 12 base-path: / 13 path-mapping.prometheus: metrics 14 exposure.include: [prometheus, health] 15 enabled-by-default: false 16 endpoint: 17 prometheus.enabled: true 18 health.enabled: true 19 server: 20 tomcat: 21 mbeanregistry: 22 enabled: true
Po uruchomieniu aplikacji na lokalnym PC wynik powyższych kroków można zaobserwować poprzez odpytanie endpoint’a:
1➜ mvn clean spring-boot:run 2 3➜ curl localhost:8090/health 4{"status":"UP"}% 5 6➜ curl localhost:8090/metrics -s | grep http 7tomcat_global_received_bytes_total{name="http-nio-8080",} 0.0 8tomcat_connections_current_connections{name="http-nio-8080",} 1.0 9tomcat_global_request_max_seconds{name="http-nio-8080",} 0.0 10tomcat_connections_keepalive_current_connections{name="http-nio-8080",} 0.0 11tomcat_connections_config_max_connections{name="http-nio-8080",} 8192.0 12tomcat_threads_busy_threads{name="http-nio-8080",} 0.0 13tomcat_global_request_seconds_count{name="http-nio-8080",} 0.0 14tomcat_global_request_seconds_sum{name="http-nio-8080",} 0.0
Kolejnym krokiem jest zainstalowanie Prometheus i Grafana i obserwacja:

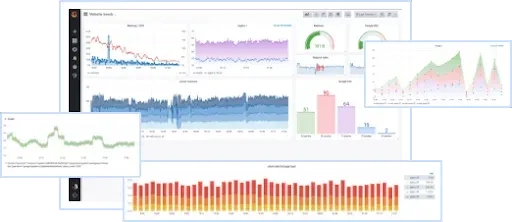
Uruchamianie serwisów sieciowych na różnych portach
Obsługa zapytań “biznesowych” jest innym zagadnieniem niż metryki. Dlatego najlepiej, żeby były dostępne na różnych portach. Ułatwi to pracę np. DevOps’om, którzy mogą chcieć wyłączyć autentykację jeśli ruch kierowany jest na port metryk lub zastosować inne reguły bezpieczeństwa.
Ułatwi to też konfigurację Istio (problem kubelet odpytujący /health vs mTLS):
1data: 2 application.yaml: |- 3 management: 4 # Different port for metrics and healthchecks solve problem Istio vs Kubelet 5 server.port: 8090
Stosowanie się do zaleceń - czy to się opłaca?
Kubernetes zaleca użycie ogólnych labelek, które tworzą jego zasoby. Biorąc pod uwagę, jak wiele aplikacji, tworzonych wokół kontraktu i zaleceń, powstaje dla Kubernetes. Takim przykładem jest Kiali, która potrafi zobrazować nasz system, jeśli trzymamy się zaleceń Kubernetes odnośnie labelek:
1apiVersion: apps/v1 2kind: Deployment 3metadata: 4 name: k8s-java-hello-world 5 labels: 6 # K8s standard label - https://kubernetes.io/docs/concepts/overview/working-with-objects/common-labels/ 7 # Tools around assume such naming convention and building product around it. Ex Istio and Kiali 8 app.kubernetes.io/name: k8s-java-hello-world 9 # K8s standard label - https://kubernetes.io/docs/concepts/overview/working-with-objects/common-labels/ 10 # Tools around assume such naming convention and building product around it. Ex Istio and Kiali 11 app.kubernetes.io/version: 1.0.0 12 # K8s standard label - https://kubernetes.io/docs/concepts/overview/working-with-objects/common-labels/ 13 # Tools around assume such naming convention and building product around it. Ex Istio and Kiali 14 app.kubernetes.io/part-of: k8s-java-hello-world

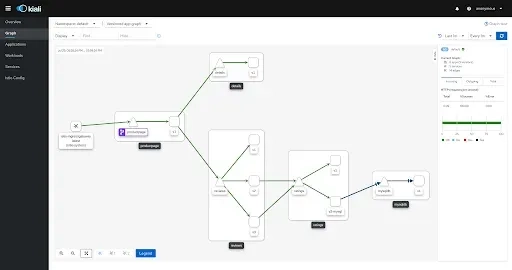
Reguła uprawnień na miarę zadań
Ta reguła dotyczy każdego środowiska – uprawnienia powinny być zminimalizowane do tych niezbędnych, a nie root/admin od początku. W przypadku Kubernetes należy ustawić securityContext w specyfikacji, aby kontener nie był uruchamiany spod root:
1spec: 2 securityContext: 3 runAsUser: 1000 4 runAsGroup: 3000 5 fsGroup: 2000
Również należy zadbać, aby sam serwis w Kubernetes używał innego konta niż default. Umożliwi to właściwą konfigurację np. IaM u dostawcy chmury, Istio itd.
1apiVersion: v1 2kind: ServiceAccount 3metadata: 4 name: k8s-java-hello-world
Aktualizacja bibliotek
Zazwyczaj aplikacja używa biblioteki Spring MVC itd. Właściciele bibliotek od czasu do czasu naprawiają znalezione w nich błędy albo problemy wydajnościowe. Teoretycznie nowsza wersja, to lepszy produkt.
Żeby trzymać rękę na pulsie, wystarczy aktywować plugin w maven albo gradle.
1<plugin> 2 <groupId>org.codehaus.mojo</groupId> 3 <artifactId>versions-maven-plugin</artifactId> 4 <version>${versions-maven-plugin.version}</version> 5 <executions> 6 <execution> 7 <phase>verify</phase> 8 <goals> 9 <goal>display-dependency-updates</goal> 10 <goal>display-property-updates</goal> 11 <goal>display-plugin-updates</goal> 12 <goal>dependency-updates-report</goal> 13 <goal>plugin-updates-report</goal> 14 <goal>property-updates-report</goal> 15 </goals> 16 </execution> 17 </executions> 18</plugin>
Weryfikacja bibliotek pod kątem bezpieczeństwa
OWASP to uznana organizacja zajmująca się bezpieczeństwem w IT – publikuje artykuły na temat znanych dziur w bezpieczeństwie i podpowiada jak im zaradzić. Co więcej, utworzyła i udostępniła wtyczkę, która weryfikuje zależności użyte w naszej aplikacji i bada czy przypadkiem nie znajdują się w bazie bibliotek (National Vulnerability Database), w których wykryto dziurę.
1<plugin> 2 <groupId>org.owasp</groupId> 3 <artifactId>dependency-check-maven</artifactId> 4 <version>${dependency-check-maven.version}</version> 5 <configuration> 6 <failBuildOnCVSS>8</failBuildOnCVSS> 7 </configuration> 8 <executions> 9 <execution> 10 <goals> 11 <goal>check</goal> 12 </goals> 13 </execution> 14 </executions> 15</plugin>
Tworzenie obrazu aplikacji Java w kontenerze
Początkowo jedynym sposobem tworzenia obrazów aplikacji w kontenerze było utworzenie i wypełnienie pliku Dockerfile i uruchomienie aplikacji Docker, która tworzy obraz zgodnie z poleceniami zawartymi w Dockerfile. Stworzenie „dobrego” obrazu wymaga wiedzy z paru technologii:
- Docker - np. pojęcie warstw obrazu
- Security – jakiego systemu operacyjnego użyć, jakie aplikacje włączyć/wyłączyć i jak je skonfigurować.
W międzyczasie powstały aplikacje, które agregują w sobie tę wiedzę i odpowiednio tworzą obrazy:
- JIB od Google’a. Narzędzie jest dostępne jako plugin do Maven i Gradle, wykorzystywane jest do skonteneryzowania aplikacji wewnątrz Google. Nie wymaga instalacji Docker. Jedno z ważniejszych cech obrazów tworzonych przez JIB jest „distroless” obraz bazowy. JIB trzyma się zasady, że kontener na produkcji powinien mieć (chociaż lepiej napisać czego nie powinien mieć) odinstalowane/wyłączone aplikacje, które nie kładą nacisku wartość biznesową albo nie są wymagane do funkcjonowania systemu operacyjnego. W ten sposób w tak utworzonym obrazie nie znajdzie się bash ani sh.
1<plugin> 2 <groupId>pl.project13.maven</groupId> 3 <artifactId>git-commit-id-plugin</artifactId> 4 <version>${git-commit-id-plugin.version}</version> 5 <executions> 6 <execution> 7 <id>get-the-git-infos</id> 8 <goals> 9 <goal>revision</goal> 10 </goals> 11 <phase>validate</phase> 12 </execution> 13 </executions> 14 <configuration> 15 <dotGitDirectory>${project.basedir}/.git</dotGitDirectory> 16 </configuration> 17</plugin> 18<plugin> 19 <groupId>com.google.cloud.tools</groupId> 20 <artifactId>jib-maven-plugin</artifactId> 21 <version>${jib-maven-plugin.version}</version> 22 <configuration> 23 <to> 24 <image> 25 ${container.registry.url}/${container.name}:${git.commit.id.abbrev} 26 </image> 27 </to> 28 <container> 29 <ports> 30 <port>8080</port> 31 </ports> 32 <creationTime>USE_CURRENT_TIMESTAMP</creationTime> 33 <jvmFlags> 34 <jvmFlag>-server</jvmFlag> 35 </jvmFlags>
- Cloud Native Buildpacks (CNB). Specyfikacja i jej implementacja utworzona na potrzeby platformy Heroku w 2011. Od tego czasu zyskała adaptację Cloud Foundry, Google App Engine, Gitlab, Knative, Deis, Dokku i Drie. CNB implementuje najlepsze praktyki przy tworzeniu OCI obrazów. Narzędzie dostępne „out of the box” w wielu CI/CD systemach jako krok do dodania do „pipeline”. Należy pobrać aplikację pack i użyć jej np. w poniższy sposób:
1export GIT_SHA="eb7c60b" 2 3pack build --path . --builder paketobuildpacks/builder:base registry.digitalocean.com/learning/k8s-java-hello-world:${GIT_SHA} --publish 4 5base: Pulling from paketobuildpacks/builder 6===> ANALYZING 7Previous image with name "registry.digitalocean.com/learning/k8s-java-hello-world:eb7c60b" not found 8===> RESTORING 9===> BUILDING 10 11*** Images (sha256:dc7bbcc2a5fd3d20d0e506126f7181f57c358e5c9b5842544e6fc1302b934afe): 12 registry.digitalocean.com/learning/k8s-java-hello-world:eb7c60b 13Adding cache layer 'paketo-buildpacks/bellsoft-liberica:jdk' 14Adding cache layer 'paketo-buildpacks/maven:application' 15Adding cache layer 'paketo-buildpacks/maven:cache' 16Adding cache layer 'paketo-buildpacks/maven:maven' 17Successfully built image registry.digitalocean.com/learning/k8s-java-hello-world:eb7c60b
Poznaj więcej możliwości Kubernetesa
Jeżeli poszukujesz kompleksowego szkolenia z kontenerów, sprawdź nasze propozycje:
Więcej szkoleń z tej kategorii znajdziesz na stronie: https://www.sages.pl/szkolenia/kategoria/chmura



